
株式会社jeki Data-Driven Lab データマネジメント部の俊です。
Google Cloud Platformに関する学習を進めるなかで、以前から気になっていたBigQuery一般公開データセットについて調べてみました。本記事ではおすすめのデータセットやサンプルクエリをあわせてご紹介します。
この記事を読んでほしい人
– BigQueryを触ってみたい人
– BigQuery一般公開データセットについて詳しく知りたい人
– データの加工やクエリの練習を手軽に行いたい人
BigQuery一般公開データセットってなに?
一般公開データセットは、BigQuery に保存され、Google Cloud 一般公開データセット プログラムを通じて一般提供されているデータセットです。この一般公開データセットは BigQuery でホストされ、ユーザーがアクセスして独自のアプリケーションに統合できます。
Google Cloud公式ドキュメントより
上記公式ドキュメントの通り、BigQuery一般公開データセットとはGoogleアカウントさえあれば誰でも利用できるデータセットです。
ブラウザ上でBigQueryを開くだけで手軽にデータセットにアクセスしてクエリを実行できるため、BigQueryの入門やクエリの練習材料に最適なデータです。
利用料金
Google では、これらのデータセットの保存費用を負担しており、プロジェクトを介してデータへの公開アクセスを提供しています。データで実行したクエリにのみ料金が発生します。毎月 1 TB まで無料です。クエリの料金の詳細をご覧ください。
Google Cloud公式ドキュメントより
一般公開データセットの利用自体は無料です。
しかしBigQueryでは毎月1TBを上限としてクエリの無料枠が設定されており、これを超える場合には支払いが発生します。
この無料枠は一般公開データセットに限らずBigQuery全体での合計処理バイト数をもとに計算されるため、他のプロジェクトでも並行して作業をしている場合には注意が必要です。
データセットの特徴
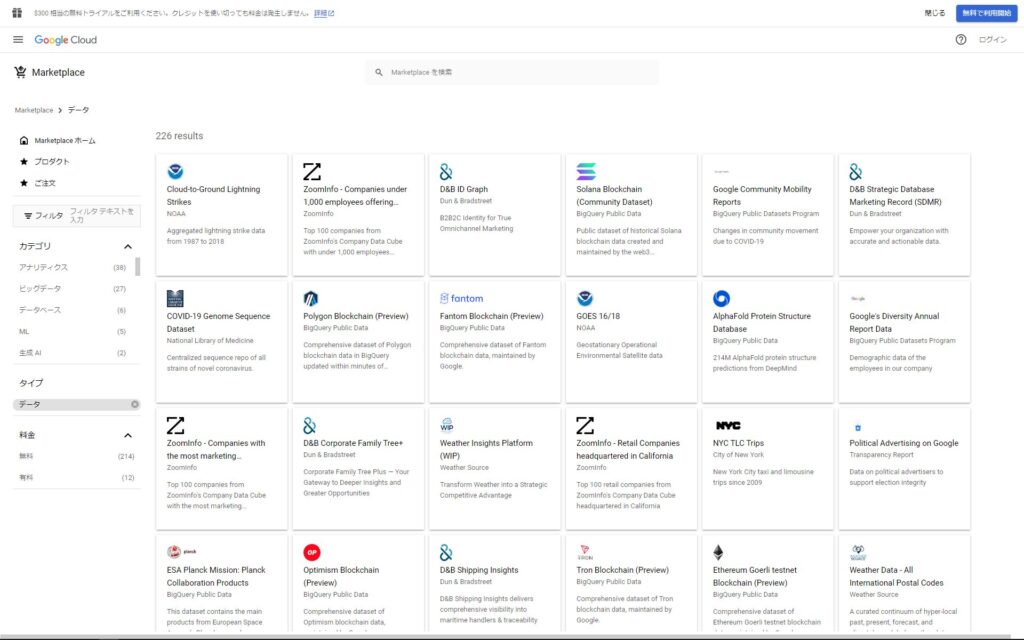
公開されているデータセットの一覧については後述するBigQueryコンソール画面だけでなく、Google Cloud Marketplaceからでも確認できます。
BigQuery一般公開データセットには226種類のデータセットが公開されており、内訳としては無料データが214個、有料データは12個という構成です(2024年2月27日時点)
これらの中にはGoogleが各種サービスを通じて取得したデータに加えて、政府機関や研究所、民間企業まで様々な外部組織から提供されたデータが含まれています。※データのジャンルとしては社会活動・経済活動に関するものが多いです。
データセットは全てBigQueryでホストされているため、外部との接続作業は一切不要です。大きいものでは数億行といった自力で作るには途方もない労力を要するサイズのデータまで用意されています。
ただ、一方で各データの構成としてはシンプルです。元は複数のテーブルにまたがっていたと思われるRDB由来のデータも、簡単のため主要カラムに絞ってジョインしたうえで単一のテーブルにまとめられているようなことが多いです。
BigQuery設定手順
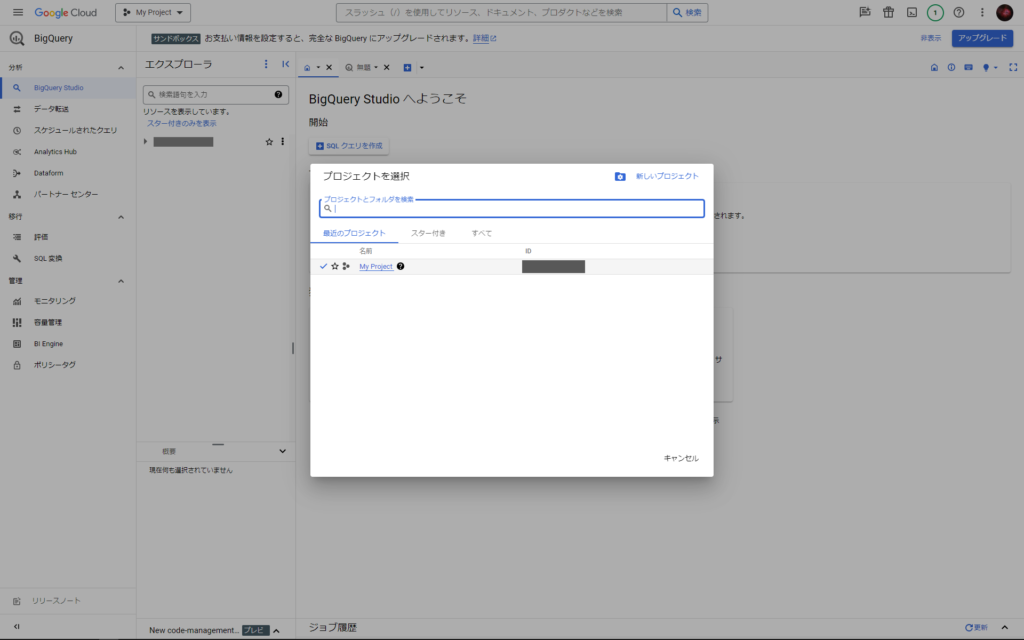
BigQueryコンソール画面にアクセスし、左上のドロップダウンからプロジェクトを選択します。
既存のプロジェクトがない場合などは右上の「新しいプロジェクト」から新規にプロジェクトを作成してください。
最後の手順として、今回使用する一般公開データセットにアクセスしましょう。
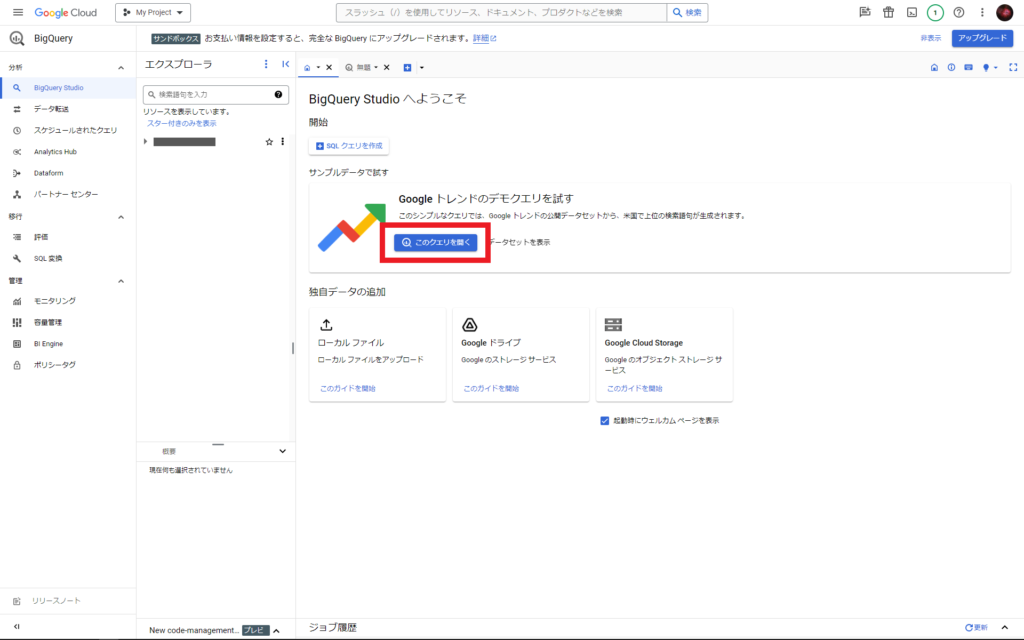
トップ画面に表示されている「このクエリを開く」をクリックします。
右のエリアに新規タブとしてサンプルクエリが作成され、左のサイドバーには一般公開データセットが一覧で表示されているかと思います。
試しに右のエリアにある「実行」をクリックしてみてください。クエリが実行されて下部に結果が出力されたでしょうか。
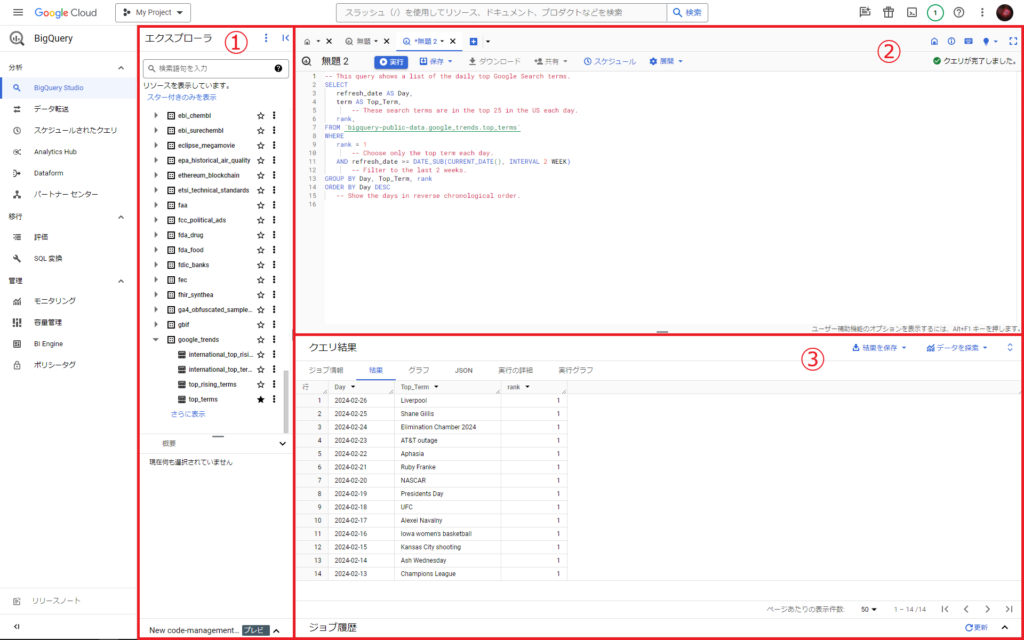
①プロジェクトに紐づいたデータセットの表示エリア
②クエリ・データセット詳細表示エリア
③クエリ結果表示エリア
大まかな使い方としては、まずは①でデータセットを選択して②で中身をざっと把握します。②の別タブでデータセットに対するクエリを書いて実行し、③で結果を確認という流れになります。
以上でBigQueryの準備は完了です。
処理バイト数の確認方法
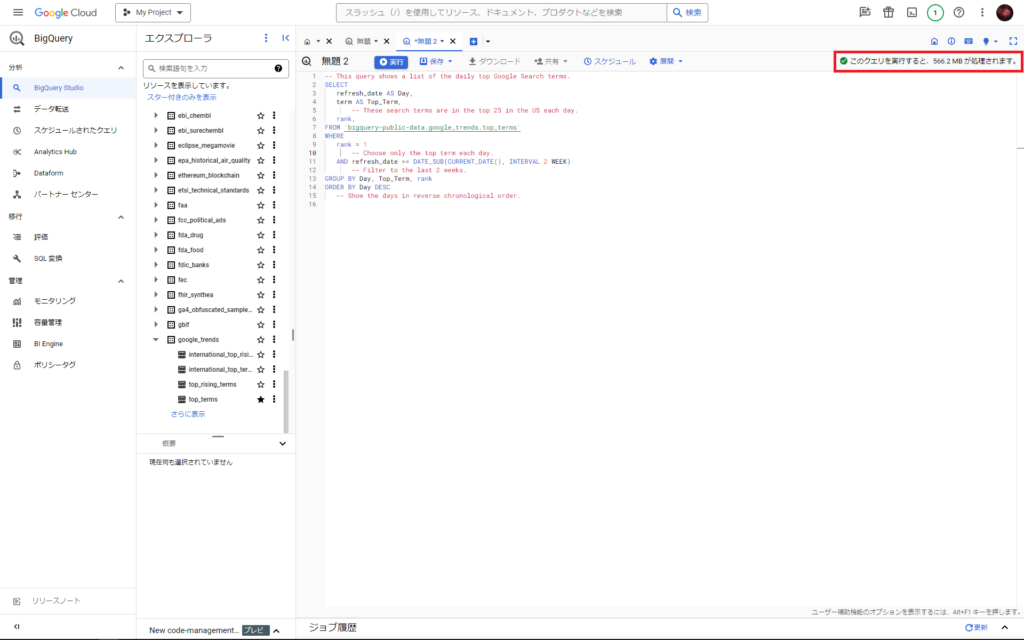
BigQueryではクエリを実行する前の段階で、処理バイト数の確認が可能です。クエリを入力すると、そのクエリによって処理されるデータサイズが予測値として右上に表示されます。
今回紹介するデータセットでもクエリによっては一発でGB単位の処理が走るようなものもあるため、 無料枠範囲内での利用の際は注意してください。
おすすめデータセット
前述の通り一般公開データセットにはさまざまなデータセットが含まれていますが、今回はより直感的に理解しやすい題材・データ構造のデータセットに絞って3つご紹介します。
Google Trends
Google Trendsは各国のGoogle検索結果をもとにしたトレンドワードのランキングをまとめたデータセットです。
先ほどのBigQuery開始手順にてトップ画面でもおすすめされているように、BigQueryの入門として試すにはもってこいです。
またこちらのデータセットは日次更新で直近のトレンドワードも確認できるため、たまに覗いてみても楽しいと思います。
テーブル構成
| テーブル名 | 説明 |
|---|---|
| top_terms | トレンドワード(米国) |
| top_rising_terms | 急上昇トレンドワード(米国) |
| international_top_terms | トレンドワード(世界) |
| international_top_rising_terms | 急上昇トレンドワード(世界) |
アメリカ国内とその他の国でテーブルが別になっている点に注意してください。
いずれのテーブルもカラム数が10以内という非常にシンプルな構造です。
クエリ例①
SELECT
refresh_date AS Day,
term AS Top_Term,
rank,
FROM `bigquery-public-data.google_trends.top_terms`
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY Day, Top_Term, rank
ORDER BY Day DESC| Day | Top_Term | rank |
|------------|--------------------------|------|
| 2024-02-26 | Liverpool | 1 |
| 2024-02-25 | Shane Gillis | 1 |
| 2024-02-24 | Elimination Chamber 2024 | 1 |
| 2024-02-23 | AT&T outage | 1 |
| 2024-02-22 | Aphasia | 1 |まずはBigQueryが用意してくれているサンプルクエリから確認します。こちらはBigQuery設定手順の中で試したクエリから不要なコメントを省いたものです。
アメリカにおけるトレンドワードについて、日別1位のワードを直近2週間分出力しています。
クエリ例②
SELECT
refresh_date AS Day,
term AS Top_Term,
rank,
FROM `bigquery-public-data.google_trends.international_top_terms`
WHERE
rank <= 10
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
AND country_name = "Japan"
GROUP BY Day, Top_Term, rank
ORDER BY Day DESC, rank| Day | Top_Term | rank |
|------------|----------------------|------|
| 2024-02-25 | 世界卓球 | 1 |
| 2024-02-25 | サウジカップ | 2 |
| 2024-02-25 | サンリオピューロランド | 3 |
| 2024-02-25 | なでしこジャパン | 4 |
| 2024-02-25 | 錦戸亮 | 5 |先ほどのクエリを少しいじって日本のトレンドワードについても見てみましょう。
テーブル名をinternational_top_termsに変更し、country_nameでJapanを指定。ワード数については日別上位10位までを表示しています。
ニュースやSNSで話題になっているものがランクインしており、一部のビッグトピックについては数日間上位をキープしていることも確認できます。
Iowa Liquor Retail Sales
アメリカのアイオワ州における酒(リキュール)の販売データです。
いつどの店でどんな酒がどれだけの数・量売れたかについて、2012年1月から月次更新されています。
テーブル構成
| テーブル名 | 説明 |
|---|---|
| sales | 販売データ |
テーブルは1つのみでジョインの必要はありません。
クエリ例①
SELECT
item_description
,ROUND(SUM(volume_sold_liters),2) AS liters_sold
FROM `bigquery-public-data.iowa_liquor_sales.sales`
GROUP BY 1
ORDER BY 2 DESC| item_description | liters_sold |
|---------------------------|-------------|
| BLACK VELVET | 15806358.16 |
| HAWKEYE VODKA | 9941784.9 |
| TITOS HANDMADE VODKA | 8911157.76 |
| FIREBALL CINNAMON WHISKEY | 5922103.75 |
| FIVE O'CLOCK VODKA | 4920096.52 | 商品別に販売された量(リットル単位)を全期間で集計し、上位から表示しています。
首位のBLACK VELVETが2位以下を圧倒しており、その販売量は1580万L。
集計期間はおよそ12年なので、平均して1日当たり3600Lほど販売されていることになります。
※元のサンプルクエリはガロン単位の集計で感覚的にわかりにくいため、リットル列を参照するよう変更しています
クエリ例②
SELECT
store_name,
address,
city,
ROUND(SUM(volume_sold_liters),2) AS liters_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
GROUP BY
store_name,
address,
city
ORDER BY
liters_sold DESC| store_name | address | city | liters_sold |
|-------------------------------------|-------------------------|--------------|-------------|
| HY-VEE #3 / BDI / DES MOINES | 3221 SE 14TH ST | DES MOINES | 7325872.26 |
| CENTRAL CITY 2 | 1501 MICHIGAN AVE | DES MOINES | 6218991.04 |
| HY-VEE WINE AND SPIRITS / IOWA CITY | 1720 WATERFRONT DR | IOWA CITY | 3116861.58 |
| SAM'S CLUB 8162 / CEDAR RAPIDS | 2605 BLAIRS FERRY RD NE | CEDAR RAPIDS | 2903274.95 |
| SAM'S CLUB 8238 / DAVENPORT | 3845 ELMORE AVE. | DAVENPORT | 1996056.9 | 販売店舗別に販売された量(リットル単位)を全期間で集計し、上位から表示しています。
州都であるDES MOINES(デモイン)に位置する店舗がツートップで顕著ですが、州内最大都市という割に3位以下では同市の店舗はあまり見られない状態です。
人口分布や他の店舗の立地などを踏まえればさらに面白い傾向が見られるかもしれません。
NYC Street Trees
ニューヨーク市内の街路樹の全数調査データです。1995年、2005年、2015年の計3回の調査結果がまとめられたデータで、樹木の分布や種類、成長状態などを確認することができます。
テーブル構成
| テーブル名 | 説明 |
|---|---|
| tree_census_1995 | 1995年の調査結果 |
| tree_census_2005 | 2005年の調査結果 |
| tree_census_2015 | 2015年の調査結果 |
| tree_species | 樹種の一覧 |
3回の調査結果が各3テーブルと、樹種マスターが1つという構成です。
データが簡略化されているせいか樹種の主キーがない点に注意してください。
全てのテーブルには樹種のラテン語表記(学名)のカラムが用意されており、樹種マスターと調査結果テーブルを結合する際にはこちらをキーとして扱うことになります。
クエリ例①
#standardsql
SELECT
spc_latin,
spc_common,
COUNT(*) AS count,
ROUND(COUNTIF(health="Good")/COUNT(*)*100) AS healthy_pct
FROM
`bigquery-public-data.new_york.tree_census_2015`
WHERE
status="Alive"
GROUP BY
spc_latin,
spc_common
ORDER BY
count DESC| spc_latin | spc_common | count | healthy_pct |
|------------------------------------|------------------|-------|-------------|
| Platanus x acerifolia | London planetree | 87014 | 84.0 |
| Gleditsia triacanthos var. inermis | honeylocust | 64263 | 85.0 |
| Pyrus calleryana | Callery pear | 58931 | 82.0 |
| Quercus palustris | pin oak | 53185 | 86.0 |
| Acer platanoides | Norway maple | 34189 | 62.0 |2015年時点で本数の多い樹種を表示しています。
また樹木は健康状態についてGood Fair Poor(良い 普通 悪い)の3段階で評価されており、それぞれの樹種のうち評価がGoodのものの割合をhealthy_pctとして併記しています。
ほとんどの樹種は健康割合が80%前後となっているなか、第5位のAcer platanoidesなど一部の樹種は60%台とかなり低い数値となっているのが興味深いです。
クエリ例②
#standardsql
SELECT
IFNULL(a.upper_latin, b.upper_latin) as upper_latin,
IFNULL(count_2015, 0) as count_2015,
IFNULL(count_1995, 0) as count_1995,
(IFNULL(count_2015, 0)-IFNULL(count_1995, 0)) AS count_growth,
(IFNULL(alive_2015, 0)-IFNULL(alive_1995, 0)) as alive_growth,
(IFNULL(dead_2015, 0)-IFNULL(dead_1995, 0)) as dead_growth
FROM (
SELECT
UPPER(spc_latin) AS upper_latin,
spc_common,
COUNT(*) AS count_2015,
COUNTIF(status="Alive") AS alive_2015,
COUNTIF(status="Dead") AS dead_2015
FROM
`bigquery-public-data.new_york.tree_census_2015`
WHERE spc_latin != ""
GROUP BY
spc_latin,
spc_common)a
FULL OUTER JOIN (
SELECT
UPPER(spc_latin) AS upper_latin,
COUNT(*) AS count_1995,
COUNTIF(status!="Dead") AS alive_1995,
COUNTIF(status="Dead") AS dead_1995
FROM
`bigquery-public-data.new_york.tree_census_1995`
GROUP BY
spc_latin)b
ON
a.upper_latin=b.upper_latin
ORDER BY
count_growth DESC| upper_latin | count_2015 | count_1995 | count_growth | alive_growth | dead_growth |
|------------------------------------|------------|------------|--------------|--------------|-------------|
| PLATANUS X ACERIFOLIA | 87014 | 0 | 87014 | 87014 | 0 |
| GLEDITSIA TRIACANTHOS VAR. INERMIS | 64264 | 0 | 64264 | 64263 | 1 |
| PRUNUS | 29279 | 0 | 29279 | 29279 | 0 |
| PYRUS CALLERYANA | 58931 | 31295 | 27636 | 27995 | -359 |
| ZELKOVA SERRATA | 29258 | 5740 | 23518 | 23612 | -94 |
...
| GLEDITSIA TRIACANTHOS | 0 | 33727 | -33727 | -33340 | -387 |
| ACER PLATANOIDES | 34189 | 109325 | -75136 | -73047 | -2089 |
| PLATANUS ACERIFOLIA | 0 | 88040 | -88040 | -87392 | -648 |1995年と2015年のデータを比較して樹種別の本数の増減を計算し、この20年での増加数の多い順に表示しています。
ステータスがAliveの樹木の増減(alive_growth)とステータスがDeadの樹木の増減(dead_growth)の合計が各樹木全体としての増減(count_growth)となる形です。
首位のPLATANUS X ACERIFOLIAの増加数と最下位のPLATANUS ACERIFOLIAの減少数がほとんど一致しており樹種名も似通っていることから、20年の間で近縁種との入れ替えが行われているのではないかと推測できます。
さいごに
今回ご紹介したものはほんの一例で、BigQuery の一般公開データセットには数多くのデータが存在します。
どのデータも非常にシンプルな構成で直感的にわかりやすい性質のものばかりなので、他にもいろいろ触ってみてください。
当社ではデータ分析支援の一環として、BigQueryを用いたデータ基盤構築も行っております。
ご興味のある方はこちらよりお気軽にお問い合わせください。