
株式会社jeki Data-Driven Lab データマネジメント部の俊です。
前回のBigQuery一般公開データセットの紹介に引き続き、今回もGCPについて学習した内容のアウトプットとして執筆しております。本コラムは2部構成となっており、GCP環境においてCSVデータをBigQueryに取り込ませる方法についてご紹介していきます。
まず前編であるこちらでは、Google Cloud StorageとBigQueryのみを用いたシンプルな取り込み方法をまとめております。
Google Cloud Functionを用いたデータ加工を前提とした自動化については後編をご覧ください。
この記事を読んでほしい人
– CSVをDBに取り込みたい人
– GCPの基礎的なアーキテクチャを知りたい人
システム概要
サービス紹介
今回のコラムで用いるGoogle Cloud Platformのサービスは以下の3つです。
| サービス名 | 役割 | AWSでいうと? |
| Google Cloud Storage | 様々なファイルをクラウドに保存できる オブジェクトストレージサービス | Amazon S3 |
| Google Cloud Functions | 指定したイベントをきっかけに関数を実行する クラウドコンピューティングサービス | AWS Lambda |
| Google Cloud BigQuery | データ分析プロダクトに最適化された データウェアハウスサービス | Amazon Redshift |
個人的な話ではありますが、GCPに触れてこなかった筆者としては、前職で使っていたAWSと同様のサービスに置き換えて考えてみると非常にわかりやすかったです。
連携イメージ
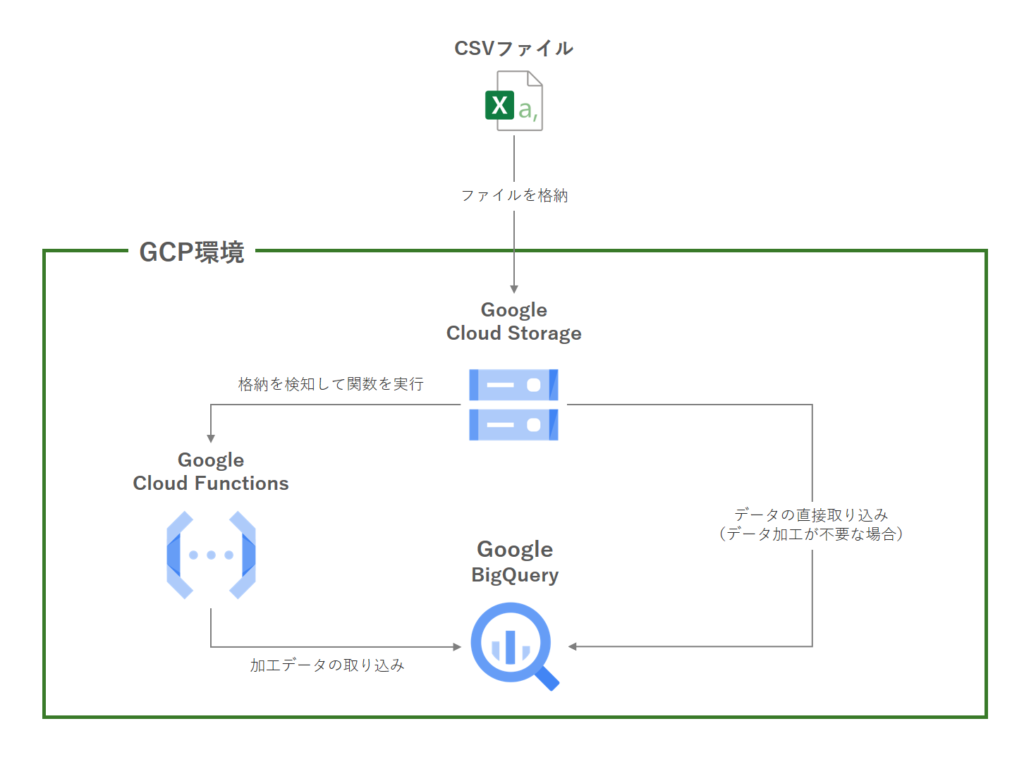
アーキテクチャとしては大きく分けて2パターンあります。
– Cloud Functionsを使わない方法
– Cloud Functionsを使う方法(後編でご紹介)
CSVファイルの中身がすでに整形済みでそのままBigQueryに保存できる場合には、Cloud Functionsは導入不要です。このケースではCloud StorageからBigQueryへ直接データを取り込むことになります。
一方でCSVデータの整形・加工が必要な場合には、Cloud Functionsを介してデータクレンジングを行ってからBigQueryにデータを取り込みます。データの自動更新にも対応しているため、汎用性が高いことが特徴です。
本題は後者なのですが、まずは前段としてよりシンプルな構成であるCloud Functionsを使わない方法についてご紹介します。
活用例
前編である今回ご紹介する内容は
– CSVをクラウドにバックアップしつつBigQuery に取り込みたい
– 高頻度でのデータ更新は行わない
– 今後更新頻度が高まる可能性があるが、ひとまずDB化したい
といった状況での活用が想定されます。
Cloud Functionsを用いると汎用性が高くなる一方で、Python等のコーディングが必要になるため開発コストがかさみます。
そのため、ひとまずはGCSとBigQuery のみの連携で進めて、状況に応じてCloud Functionsを導入するといったように後から機能拡張することも可能です。
逆にデータの自動更新には対応していないため、初めからバッチ更新が前提となっている場合には後編でご紹介するCloud Functionsを用いたアーキテクチャをご参照ください。
取り込み手順
GCS設定
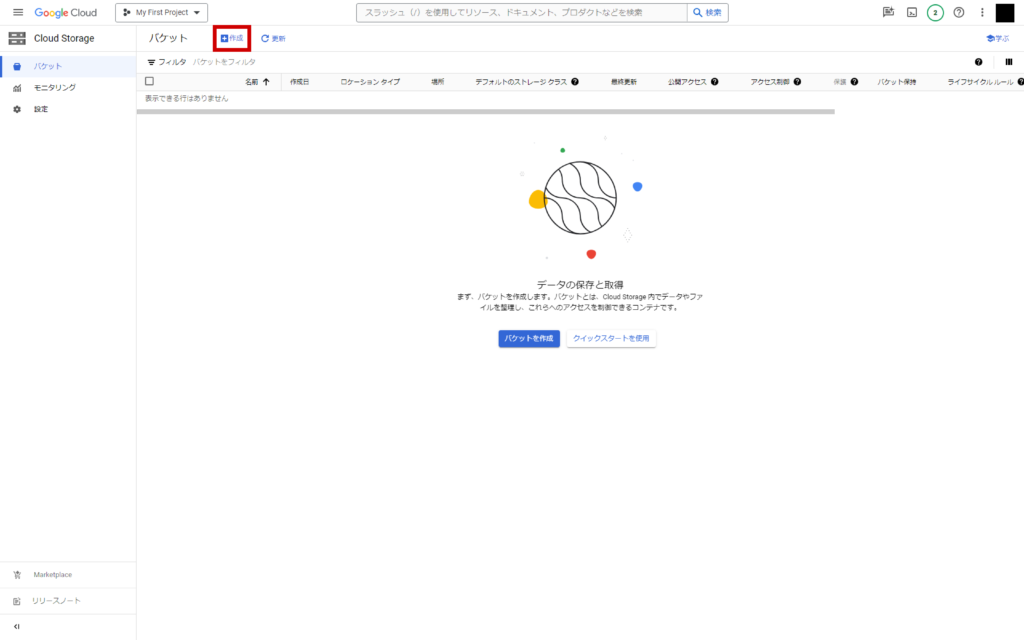
GCSコンソールページから「作成」をクリック
バケットに名前を付けます。以降の設定はデフォルトのままで「作成」をクリック。
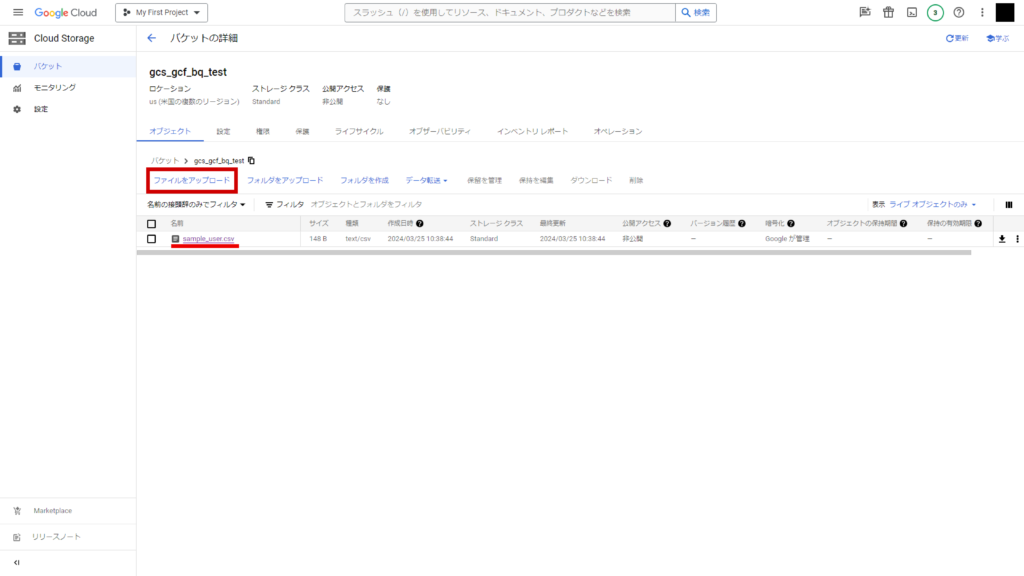
バケットが作成されますので、こちらに適当なCSVをアップロードします。
「ファイルをアップロード」からファイルを選択するか、ファイルエクスプローラーから直接ドラッグアンドドロップのいずれかでアップロードできます。
今回は例として下記のようなsample_user.csvを作成しました。
id,mail,username
0001,abc123@mail.com,JDDL一郎
0002,def456@mail.com,JDDL二郎
0003,ghi789@mail.com,JDDL三郎※文字コードはUTF-8
これでGCS側の設定は完了です。
BigQuery設定
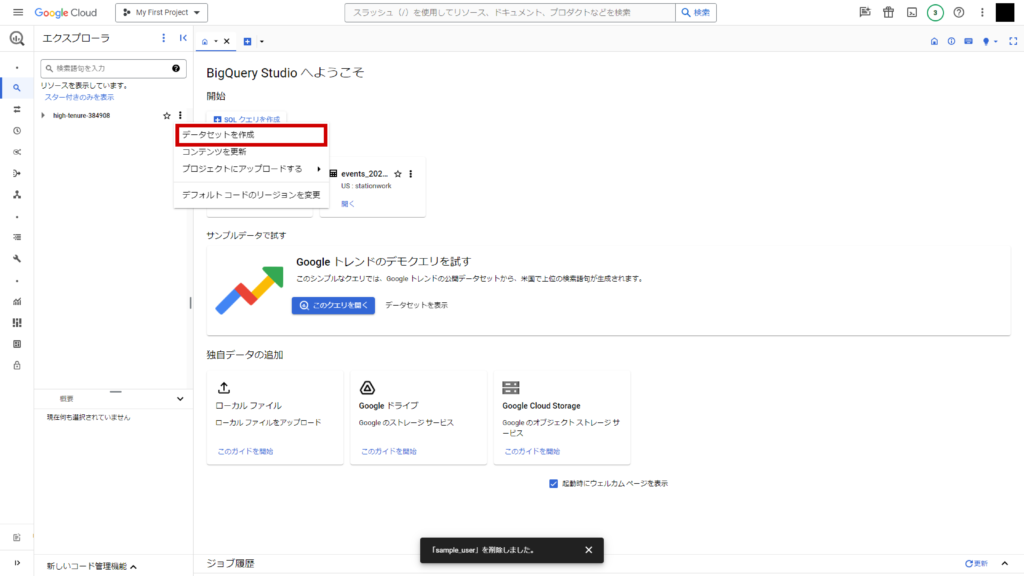
BigQueryコンソールページにアクセスします。
任意のプロジェクトIDを選択し、右の三点ボタンから「データセットを作成」をクリック。
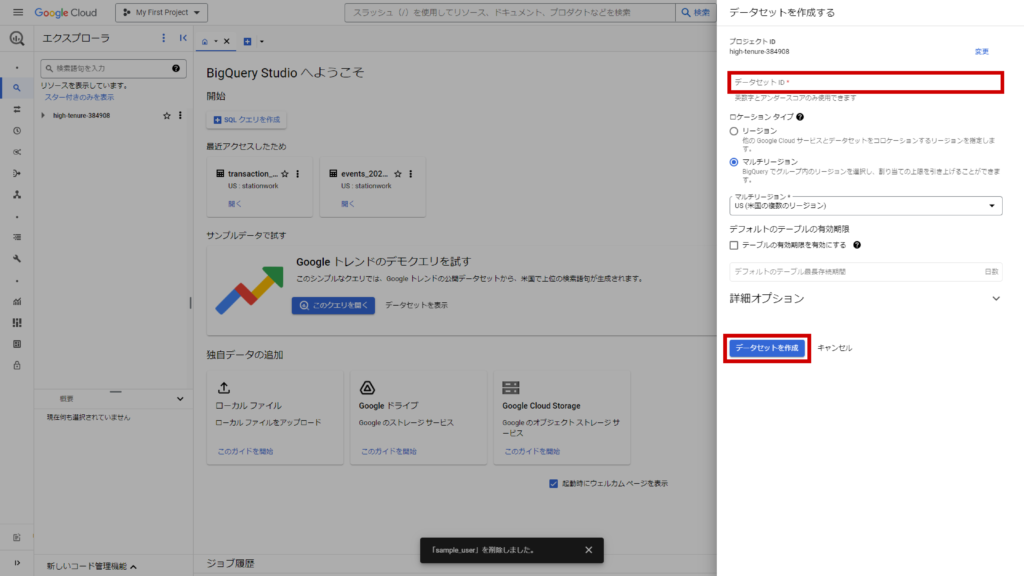
データセット名を入力し、他はデフォルトのままで「データセットを作成」をクリック。
今回はデータセット名をsample_datasetとしました。
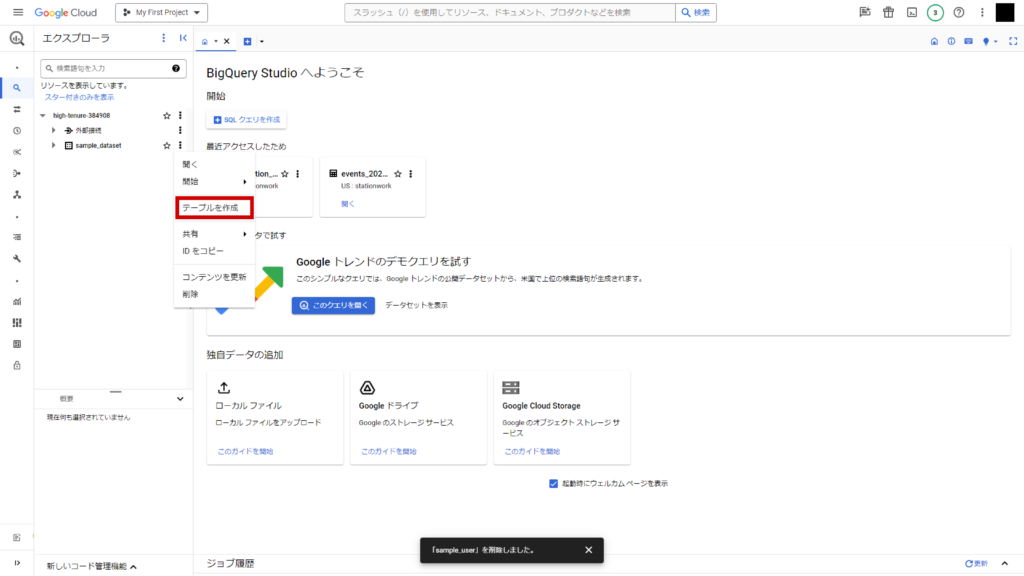
作成されたデータセットの右の三点ボタンから「テーブルを作成」をクリック。
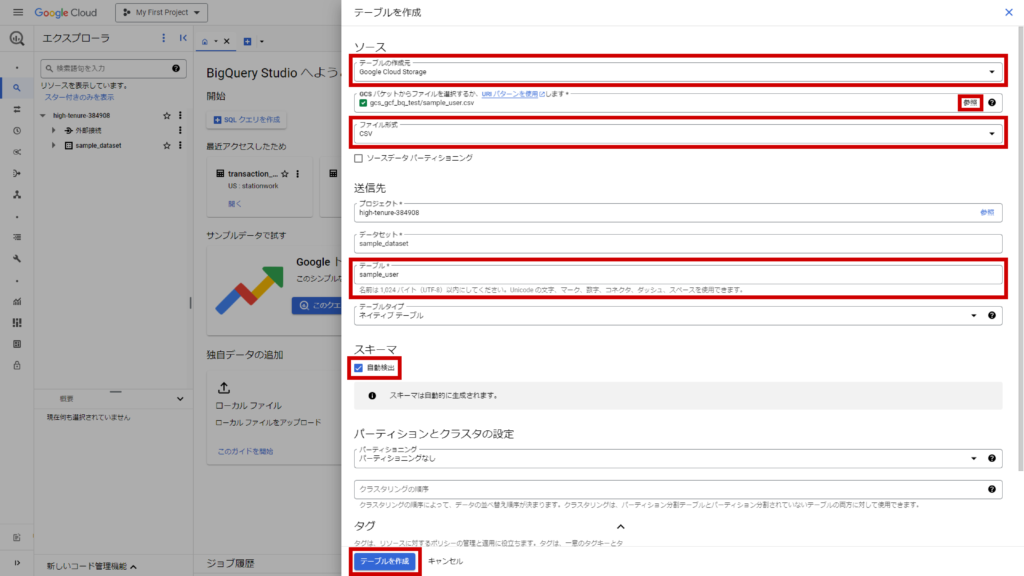
– テーブルの作成元→Google Cloud Storage
– ファイル選択→右の「参照」から先ほどアップロードしたsample_user.csvを選択(URIにはワイルドカードを含めることができるため、複数ファイルをまとめて1つのテーブルに取り込むことも可能です)
– ファイル形式→CSV(自動で選択されます)
– テーブル名→sample_user
– スキーマ→自動検出にチェックを入れる
– その他の項目→デフォルト
上記設定で「テーブルを作成」をクリックします。
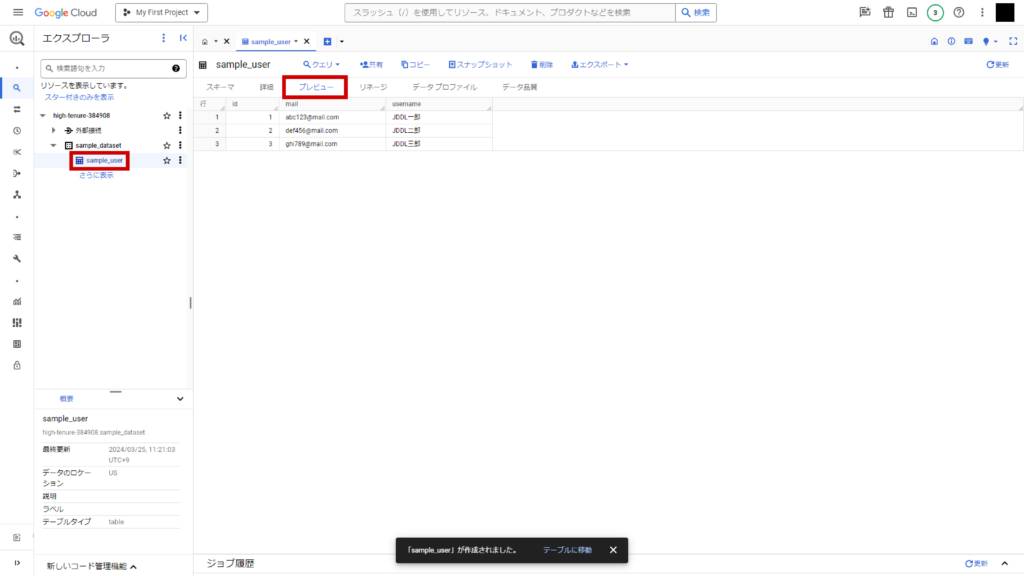
sample_datasetデータセット配下にsample_userテーブルが作成されました。
テーブルのプレビューを確認すると、CSVの中身が反映されていることが確認できます。
これで、CSVファイルのBigQuery への取り込みは完了しました。
さいごに
CSVをDB化するにあたって、GCPコンソール上で完結するシンプルな方法をご紹介しました。
次回の後編ではさらにステップアップして、GCSへのアップロードをトリガーとしてBigQuery を自動で更新する方法について解説いたします。
当社ではデータ分析支援の一環として、GCPを用いたデータ基盤構築も行っております。
ご興味のある方はこちらよりお気軽にお問い合わせください。